From Cloud Native to AI Native: Why Your AI Architecture Needs a Reality Check
Discover why AI Native architectures are the future, learn how to avoid vendor lock-in, build flexible systems, and leverage multiple AI models for resilience and innovation.
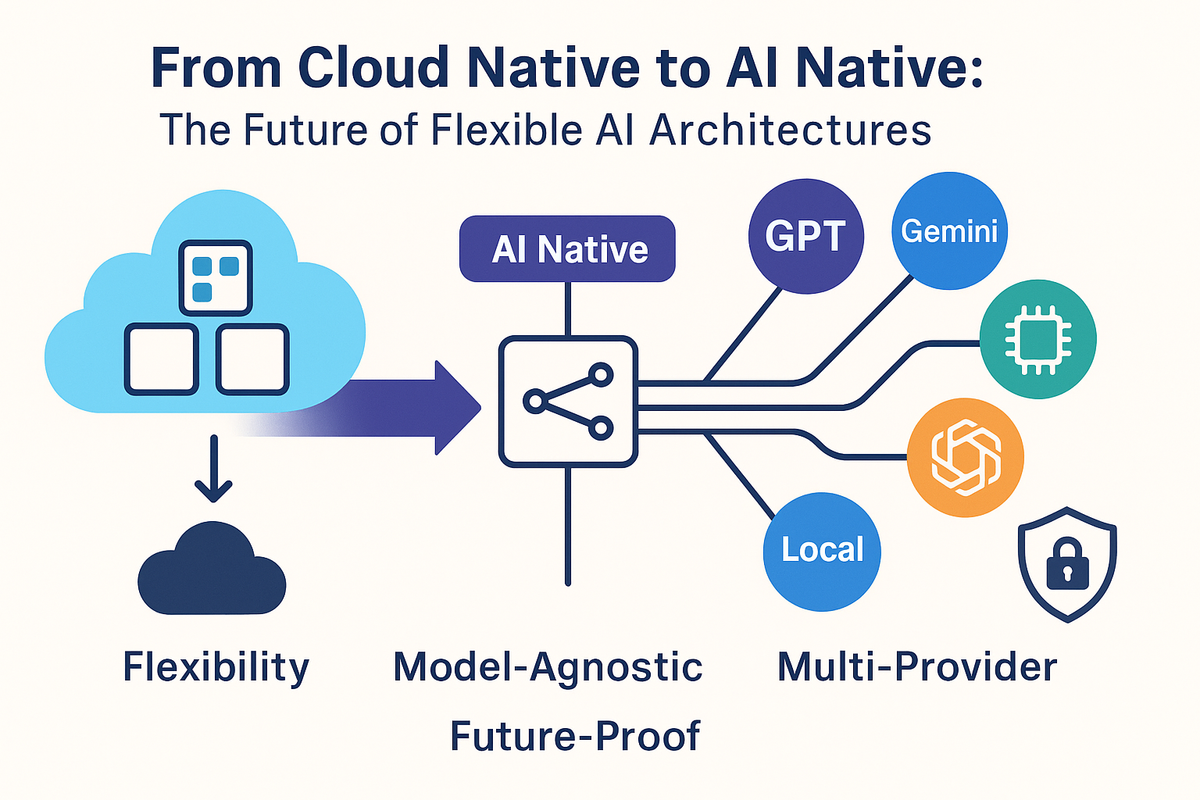
Remember when “Cloud Native” became the gold standard for building applications? Suddenly, everything had to be containerized, microservice based, stateless, and ready to move to whichever cloud provider offered the most free credits or the least amount of hassle. It was liberating, disruptive, and meant you could finally break free from vendor lock-in.
Fast forward to today: We’re at the dawn of the AI era. Yet as companies race to wire up their products to the latest shiny LLM or API, I can’t shake the feeling that we’re repeating old mistakes that we learned pre-Cloud Native times. However, with AI the lock-in is even tighter than we knew it previously. If “Cloud Native” was about freedom and flexibility, shouldn’t our AI architectures aim for the same?
What Does “Cloud Native” Really Mean?
Before “Cloud Native,” deploying applications felt like putting a stamp in the middle of a room, turning off the lights, and jumping up with your tongue out, trying to hit the stamp. A shot in the dark, and you smacked your head against the ground a lot!
Applications were tightly coupled to their infrastructure. If you changed clouds, you were basically starting from scratch. My favorite diagrams, which I have used for countless presentations, is the Spaghetti vs. Lasagna vs. Ravioli software architecture comparison.

Essentially, we are back to the Spaghetti era of software development. Spaghetti code used to be copying and pasting code from Stack Overflow from all sorts of sources. Then, to untaggle the code or upgrade was like pulling out a single piece of spaghetti from your plate while not trying to make a mess.
The Current State of AI Architectures: Are We Heading for Lock-In 2.0?
Right now, most AI-powered apps connect directly to a single AI provider OpenAI, Anthropic, Google, you name it. This works great... until it doesn’t...
Stay Updated
Get actionable AI & tech insights delivered every Friday. No fluff, just value.
Subscribe to The Weekly Byte →- Vendor lock-in: If your provider changes pricing, policies, or suddenly decides to use your data for their own model, you're screwed.
- Innovation bottlenecks: New models and breakthroughs appear almost weekly, but switching is hard when your architecture is glued to a single API.
- Compliance and data residency: Need your data to stay in your home country, or want to run on-prem for privacy? Good luck if you’re tied to one of the big AI providers.
We are riding the wave of AI exponential growth, but most architectures are acting like it’s 2015.
Introducing the “AI Native” Mindset
So, what does “AI Native” mean? It’s not just adding an LLM to your stack and calling it a day.
AI Native is about architecting your systems from the ground up to be:
- Model-agnostic: Able to swap out AI providers without rewriting everything.
- Composable: Plug in different models for different tasks (text, vision, translation, you name it).
- Resilient: If one model fails or underperforms, reroute traffic to another.
- Ready for BYOM (Bring Your Own Model): Whether it’s a self-hosted open-source model or the latest SaaS LLM.
Think of it as the Kubernetes of AI: orchestration, abstraction, and freedom.
Benefits of AI Native Design
Why bother with this extra complexity? Because the future you will thank you.
- Flexibility: Swap models as better ones emerge without having to rewrite your app.
- Resilience: If a provider changes terms or goes offline, you’re not left in the dark.
- Competitive edge: Use the best model for each use case—GPT-4 for chat, Gemini for search, local models for compliance.
- Compliance: Easily route sensitive data to compliant models, whether in-country or on-prem.
In a rapidly changing AI landscape, agility isn’t a nice-to-have...it’s survival!!
How to Build AI Native Architectures
Ready to go AI Native? Here’s how to start:
1. Abstract Your AI Layer
- Use adapter patterns, SDKs, or libraries (think LangChain, Haystack, LlamaIndex) that let you plug in different backends.
- Design your APIs so that the rest of your app doesn’t care which model is in use.
2. Decouple Business Logic from AI Providers
- Treat the AI as a service, not a dependency.
- Store prompts, fine-tuning data, and model configs in a way that’s portable between providers.
3. Invest in Monitoring and Routing
- Track latency, accuracy, and cost for each provider.
- Build in smart routing to send requests to the best provider for the task, region, or compliance need.
4. Embrace Open Source
- Keep an eye on open-source models, they’re catching up fast.
- Consider hybrid architectures: mix SaaS models for general tasks and self-hosted models for sensitive data.
Challenges and Trade-offs
Let’s be real: building AI Native isn’t all unicorns and rainbows.
- Complexity: More moving parts mean more things can break and more things to maintain.
- Latency: Routing and abstraction can add overhead.
- Monitoring: It’s harder to debug across multiple providers.
- Analysis Paralysis: The “paradox of choice” is real with so many models.
But the benefits: agility, resilience, and freedom far outweigh the challenges, especially as the ecosystem matures.
Conclusion: Don’t Just Go Cloud Native, Go AI Native!
The AI landscape is moving faster than a caffeinated squirrel, and locking yourself to a single vendor is like buying a one-way ticket on a rollercoaster you don’t control.
AI Native architectures aren’t just a technical luxury; they’re a strategic necessity for innovation, compliance, and—let’s face it—your sanity. Don’t repeat yesterday’s mistakes. Architect for flexibility, and you’ll be ready for whatever the next AI breakthrough brings.
Ready to build AI Native? Start small, abstract aggressively, and future-proof your stack before the next wave hits. Your codebase and Ops teams will thank you.
Like this article? Get more AI and tech strategy insights every week—subscribe to The Byte newsletter!



